|
There has been much controversy regarding the origin of the Wuhan coronavirus. It appears that both possibilities, naturally occurring or man-made, are legitimate enough to be debated fully. However, although voices on social media are equally strong from both sides, when it comes to written pieces, there is a predominance of scientific literature and other forms of writing that were produced to disapprove the “conspiracy theory”. In contrast, not nearly as much literature or other forms of substantial writing have been put out to describe or argue for the other possibility – this virus is man-made. My goal here is to use scientific evidence and logical thinking to evaluate, and legitimate, the possibility that the Wuhan coronavirus (2019-nCoV, SARS2-CoV, etc.) is of non-natural origin. Importantly, I will base my reasoning on solid, credible evidence; I will exclude any unqualified evidence that may have been thrown in by the Chinese Communist Party (CCP) with an intention to disturb the “investigation” and thereby cover up the truth. My role or perspective here can be considered as a combination of a scientific reviewer, a detective, and a judge on a criminal trial. Why are people suspicious of the origin of the Wuhan coronavirus This has a lot to do with how the sequence of this virus (in other words, its genome) compares with those of related coronaviruses. When comparing sequences, one can compare either gene sequences or protein sequences. For viruses, however, this makes almost no difference as the whole genome of a virus is practically translated into proteins (in fact, a virus typically produces a single polyprotein by translating its entire genome and then cuts this long polyprotein at specific places to produce a set of particular proteins for specific use). Here, we will compare different viruses only on their protein sequences. By doing such a comparison, one can see that the Wuhan coronavirus is about 86% identical to the SARS coronavirus, which caused a pandemic back in 2003. This level of sequence identity basically says that the Wuhan coronavirus could not have come from SARS, something the field agrees unanimously. At the same time, the Wuhan coronavirus is STRANGELY similar to two bat coronaviruses, ZC45 and ZXC21. Overall, the sequence of either of the two bat coronaviruses is 95% identical to the Wuhan coronavirus. In fact, for most part of the genome, such level of identity is maintained or even surpassed. The E protein, in particular, is 100% identical. The nucleocapsid is 94% identical. The membrane protein is 98.6% identical. The S2 portion (2nd half) of the spike protein is 95% identical. However, when it comes to the S1 portion (1st half) of the spike protein, the sequence identity suddenly drops to 69%. This pattern of sequence conservation, between either of the closely related bat coronaviruses and the Wuhan coronavirus, is extremely rare and strange! This is extremely rare because natural evolution typically takes place when changes (mutations) occur randomly across the whole genome. You would then expect the rate of mutation being more or less the same for all parts of the genome. Could other forms of evolution lead to such a strange pattern of sequence identity? Yes, there is one evolutionary event that could lead to drastic changes in only one part of the genome. It is what is called “recombination”. We would defer to the next section to explain why recombination is also practically impossible in this case. For now, let’s fix our eyes on the part that is seeing this sudden drop of sequence identity, the S1 portion of the spike protein.  Figure 1. Coronavirus particle with spike proteins (red) decorating its surface. Image from the CDC website (not a photo of a real virus, but a model generated based on scientific knowledge). Spike proteins are the protrusions that you see on the outside of the virus particle (Figure 1). They are literally responsible for the name “corona” as they make the virus look like a “crown”. However, spike proteins are located here for reasons beyond decoration. They are actually the “key” that coronaviruses use to open the “lock” so that viruses can enter our (host) cells. Figure 2 shows the structure of the spike protein of the SARS virus (such structure images are as real as photos of actual people). Given the sequence similarity/conservation here, the spike protein of the Wuhan coronavirus would look pretty much the same, which is indeed confirmed by a recent publication (1). 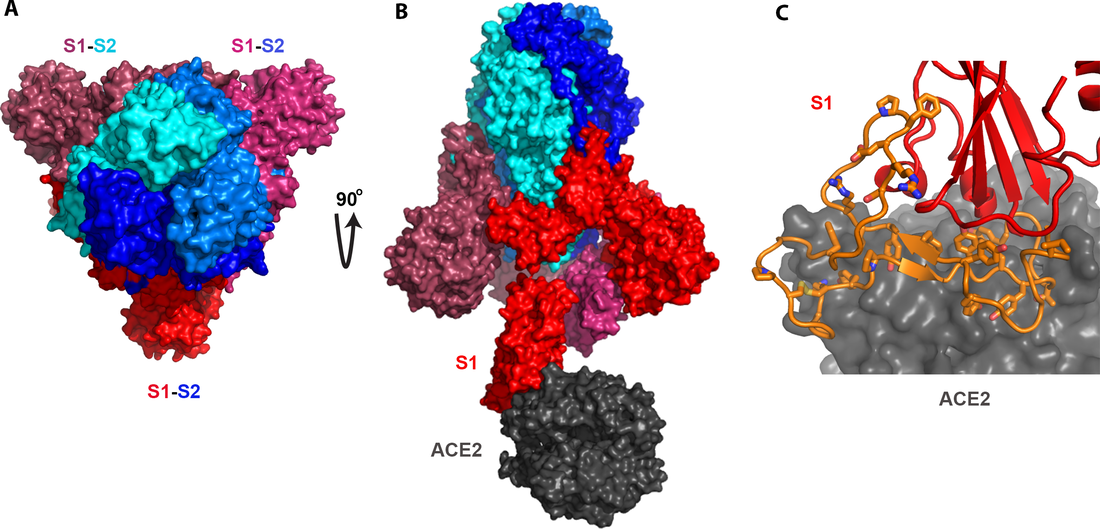 Figure 2. Structure of the SARS spike protein and how it binds to human ACE2 receptor. Pictures generated using the published structure (PDB ID: 6acj) (2). A) Three spike proteins, each consisting of a S1 half and a S2 half, form a trimer. B) The S2 halves (shades of blue) are responsible for trimer formation, while the S1 portion (shades of red) is important for binding human receptor ACE2 (dark gray). C) Details of the binding between S1 and human ACE2. The part of S1 that is important and sufficient for binding are colored in orange, with most crucial amino acid sidechains shown as sticks. This orange piece is presumably what’s “taken out of” SARS spike and “inserted” into a bat coronavirus spike protein, thereby creating a novel human-infecting coronavirus. Three spike proteins have to come together to function properly as the “key”. This three-protein assembly is what they call a “trimer”. To form this trimer, you would need the blue portion of the spike protein, which is referred to as S2 of spike. This S2 part can be regarded as the part of the “key” that you hold with your fingers; it does not actually go into the lock. However, for this “key” to work, S2 has to be there and has to preserve the ability of forming trimers. The other half of spike, the red portion or what is referred to as S1, is responsible for binding the host receptor. S1 can be considered as the portion of the “key” that literally enters the “lock”. It has to fit precisely to the delicate shape of the “lock” (host receptor) so that the “door opening” action can be accomplished. Whether or not a particular “lock” can be opened by a specific “key” is decided exclusively by this S1 part of spike. In other words, S1 of a coronavirus dictates which host(s) or cells the virus can infect. Now you may be able to appreciate what I call extremely strange. While everything else of the Wuhan coronavirus remains almost identical to the two bat coronaviruses, the S1 portion, which dictates which host a coronavirus targets, has changed significantly from the two bat coronaviruses to the Wuhan coronavirus. Let’s zoom in further (Figure 2C) and look at the exact part on S1 that dictates whether or not S1 binds a host receptor (in this case, the human ACE2 protein). This most critical part of S1 is a relatively small stretch of amino acids, labeled in orange in Figure 2C with important residues shown as sticks. This part includes everything needed for interacting with the human ACE2 receptor. You will see below how this segment, known to be unique to the SARS spike and sufficient for its interaction with human ACE2, is practically “copied” over by the Wuhan coronavirus. 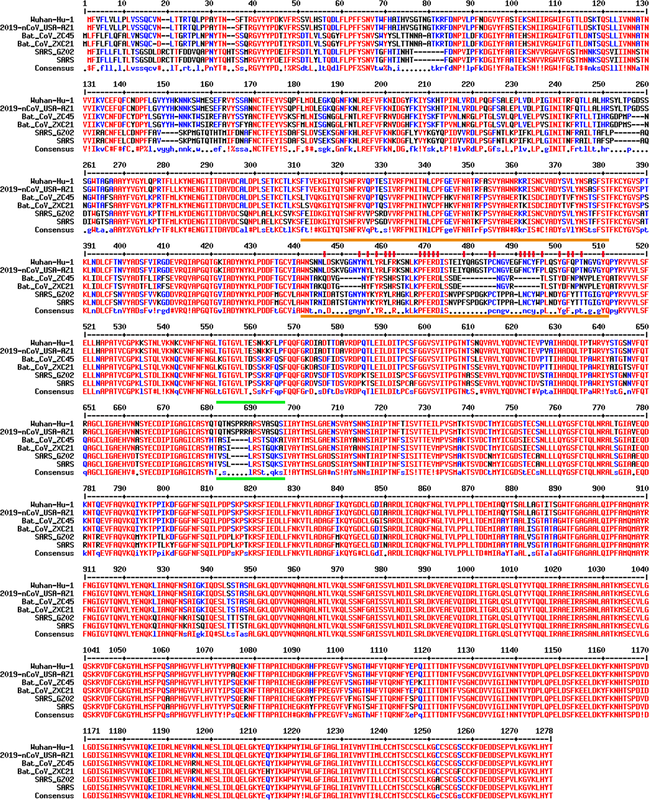 Figure 3. Sequence alignment of the spike proteins from relevant coronaviruses, including viruses isolated from current pandemic (Wuhan-Hu-1, 2019-nCoV_USA-AZ1), closely related bat coronaviruses (Bat_CoV_ZC45, Bat_CoV_ZXC21), and SARS coronaviruses (SARS_GZ02, SARS). Region marked by orange lines is the segment important for interaction with human receptor ACE2. Crucial residues for interaction are additionally highlighted by a red stick on top. Region marked by green lines is a furin-cleavage site that exists only in the Wuhan coronaviruses but not in any other beta coronaviruses. Alignment was done using the MultAlin webserver (http://multalin.toulouse.inra.fr/multalin/).
Figure 3 is the sequence alignment of the spike proteins from six coronaviruses. Two are viruses isolated from current pandemic (Wuhan-Hu-1, 2019-nCoV_USA-AZ1); two are closely related bat coronaviruses (Bat_CoV_ZC45, Bat_CoV_ZXC21); two are SARS coronaviruses (SARS_GZ02, SARS). By glancing through this figure, you can easily tell that the second half of spike (690 and beyond), namely S2, look pretty much the same for all six viruses. The difference is in the front half (1-~690), or the S1 portion. Now if you look at the top four sequences — the two Wuhan coronaviruses and two bat coronaviruses, you can see that they are largely the same across the S1 half of spike. Only a couple of places are different. However, the details of these differences and the way the human and the bat viruses differ from each other here in S1, in my and many other people’s eyes, practically spell out the origin of the Wuhan coronavirus – it is created by people, not by nature. First important difference is what is highlighted in between two orange lines in Figure 3. Clearly, this part of the Wuhan coronavirus spike differs significantly from those of the bat virus spikes, despite the overall high identity between them. Intriguingly, this same segment of the Wuhan coronavirus resembles, on a great deal, the corresponding piece on the SARS spike protein. Indeed, this is precisely the region highlighted in Figure 2C in orange. As we have pointed out earlier, this segment contains everything needed for human ACE2 interaction. Here, it seems that this critical piece was “copied” from the SARS spike protein and then “pasted” into a bat coronavirus. There are of course differences between these two, which may make it seem unlikely a direct “copy and paste”. However, careful examination shows that all residues essential for binding (orange sticks in Figure 2C and residues highlighted by red short lines in figure 3) are either precisely preserved or substituted with residues of similar properties. At the same time, differences lie mostly at residues non-essential for binding ACE2. Judging from this observation, one can safely envision that not only Wuhan coronavirus spike will bind ACE2 but also it will bind ACE2 exactly the same way that SARS spike does (Figure 2BC). For the two bat coronaviruses here, given how they lack many of the key residues (what is marked by red sticks in Figure 3) for binding human ACE2, it is easy to predict that these two bat viruses would not be able to infect human. The Wuhan coronavirus, while being almost identical to their bat relatives (ZC45 and ZXC21) everywhere else, has somehow “inherited” the critical, short piece from SARS spike to replace the incompetent piece in the bat coronavirus spike. As a result of this miraculous “replacement” in S1 — all key residues preserved and many non-essential residues changed, the Wuhan coronavirus has practically “acquired” the ability to infect humans, something its closest bat relatives do not have. Could natural evolution achieve something this precise and, at the same time, this deceptive??? If you have not been “awed” enough, let’s move on to appreciate magic trick #2. Please look at the region marked by two green lines in Figure 3. Here only the Wuhan coronaviruses contain an additional piece, SPRRA. Importantly, this added piece allows the spike protein to be readily cleaved by a host protease enzyme – furin, a desirable property known to produce more infectious viruses in the case of influenza. Note that no beta coronaviruses in the same lineage (lineage B), except this new Wuhan coronavirus, contain such a furin-cleavage site. Further explanation on why these changes could not have come from nature We have briefly explained why random mutations could not result in the weird pattern of sequence identity between the Wuhan coronavirus and related bat coronaviruses, ZC45 or ZXC21. Let’s dig a little deeper here. Although the spike proteins of different coronaviruses are more likely to differ, greater discrepancy in S1 may only be expected if two viruses have been long separated during evolution and have adapted, through random mutation, to their respective hosts for a long, long time. In that scenario, the overall sequence identity would be low as well. In the present case, however, the sequence identity between either of the bat coronavirus and the Wuhan coronavirus is over 95%, suggesting these two viral lineages must have diverged from each other fairly recently. Therefore, a sequence identity of 69% for the S1 portion of spike protein is simply insane. The S1 of Wuhan coronavirus could not have originated from the S1 of a bat coronavirus, a recent common ancestor that the Wuhan virus shares with ZC45 and ZXC21, through random mutations. Now let me explain why recombination also could not be responsible for the observed pattern. What happens in a recombination event is that one segment of a gene can be “replaced” by a similar segment from another gene. In evolution, recombination events happen much less frequently than random mutations. When recombination happens, however, it often brings abrupt changes to certain areas of the genome. If naturally-occurring recombination event(s) lead to the creation of the Wuhan coronavirus, how would it transpire? First, it would have to take place when an ancestor bat coronavirus, something very similar to ZC45 or ZXC21, co-existed with another coronavirus in the same cell of the same animal. Under extremely rare circumstances, recombination may occur, where a random piece in the ancestor’s genome is replaced by a similar but different piece from the other coronavirus. Importantly, to go from such ancestor to the Wuhan coronavirus, one combination event is not enough. What has to happen is that recombination has to take place twice during the evolution of the Wuhan coronavirus. In one occasion, the ancestor bat coronavirus would have to acquire, through recombination with a SARS-like coronavirus, the precise short segment of S1 that is responsible for human ACE2 interaction (region highlighted in orange in both Figure 2 and Figure 3). In another occasion, the “improved” bat coronavirus would further swap in a furin-cleavage site through recombination with yet another coronavirus that carries a furin-cleavage site between its S1 and S2 of spike. Also, again, given the overall high sequence identity (95%) between the bat coronaviruses and the Wuhan coronavirus, it is reasonable to believe that these two diverged from each other fairly recently. Therefore, both recombination events must have taken place fairly recently as well. Now, we know that SARS crossing over to infect human is a very rare event. To have another SARS-like sequence exist in nature so that the ancestor bat coronavirus can do recombination with is a very unlike event. Not to mention that this SARS-like virus must have a spike that binds ACE2 the same way as SARS and yet the piece of S1 that is most critical for binding ACE2 would differ with that of SARS spike only at non-essential sites. On top of that, furin-cleavge site has not been observed in any beta coronaviruses in the same lineage so far. Although similar furin-cleavage sites have been observed in other coronaviruses, none of them contains the same exact sequence. Therefore, the chance that the furin-cleavage site in the Wuhan coronavirus was obtained through recombination with another furin-cleavage-site-containing coronavirus is very low. Now, what are chances for both of these next-to-impossible recombination events to take place? My answer is NO CHANCE. This Wuhan coronavirus cannot be coming from nature. Why some literature has to be excluded in the analysis Someone who has been following the recent literature on this topic would point out that the above analysis failed to take into account some crucial evidence. Such evidence, coincidentally, supports a natural origin of the Wuhan coronavirus. Then how dare I leave it out in my analysis? The short answer: that “evidence” was very likely fabricated. Please allow me to switch my mode now, from a scientist to a detective or a judge. If we consider this matter as a crime under investigation, then we have so far one big suspect, Dr. Zhengli Shi from the Wuhan Institute of Virology and the biosafety level 4 (P4) lab for virology research. As the top coronavirus expert in China, since the beginning of the outbreak, Zhengli Shi has been singled out as THE suspect who may have created this virus, which somehow leaked out of the P4 lab. Intriguingly, Shi published an interesting paper in Nature a couple of weeks ago (3). There she compared the freshly obtained sequence of the Wuhan coronavirus with those of other beta coronaviruses, which allowed her to delineate an evolutionary path of this new virus. All of a sudden, out of nowhere, she reported a bat coronavirus, RaTG13, which shares high sequence identity with the Wuhan coronavirus. Strikingly, between RaTG13 and the Wuhan virus, the mutational rate is low (or sequence identity is high, 98.5%) for all parts of the genome, including the spike protein. If we have questioned the origin of the Wuhan coronavirus because of the weird pattern of sequence conservation between the Wuhan coronavirus and the two bat coronaviruses, ZC45 and ZXC21, then RaTG13 does not show any concern in that regard. Here, the spike protein is just as conserved as other proteins. From the first look, it seems that RaTG13 belongs to the same small lineage as the Wuhan coronavirus and that the two must share a very recent common ancestor. Such finding strongly suggests a natural origin of the Wuhan coronavirus. This paper reporting the RaTG13 coronavirus (3) is the evidence that I “failed” to take into account in the earlier analysis. According to credible sources, Shi has admitted to several individuals in the field that she does not have a physical copy of this RaTG13 virus. Her lab allegedly collected some bat feces about 7 years ago and analyzed these samples for possible presence of coronaviruses based on genetic evidence. To put it into plainer words, she has no physical proof for the existence of this RaTG13 virus. She only has its sequence information, which is nothing but a string of letters alternating between A, T, G, and C. Can the sequence be fabricated? It cannot be any easier. It takes a person less than a day to TYPE such a sequence (less than 30,000 letters) in a word file. And it would be a thousand times easier if you already have a template that is about 98% identical to the one you are trying to create. Once the typing is finished, one can upload the sequence onto the public database, without being really questioned for its authenticity or correctness. Once uploaded and released, such sequence data becomes public and can be used legitimately in scientific analysis and publications. Then, can this RaTG13 sequence be used as evidence in judging the matter? Well, remember, a central part of the matter is whether or not this Wuhan coronavirus is engineered or created by ZHENGLI SHI. It is Shi, not anybody else, who is the biggest suspect of this possible crime that is grander than any other crime ever committed in human history. Given the circumstances, if the evidence she raised to prove herself innocent is nothing but a bunch of letters recently typed in a word file, should anyone treat it as valid evidence? Unfortunately, in several recent reports, scientists indeed based their analyses on this RaTG13 sequence and thereby reached conclusions such as the Wuhan coronavirus is a result of natural evolution. I hope you now agree that these conclusions could not be trusted because they are based on data that is most likely FABRICATED BY SHI. Now, let us think about this from the other direction. The RaTG13 virus has a highly alarming sequence. Glancing at the sequence of the spike protein of this virus, any expert would immediately realize that this virus resembles SARS in its potential in binding human ACE2 and therefore may very likely be able to infect humans. Shi herself is such an expert. According to Shi, her lab studies bat coronaviruses so that they could someday predict novel coronavirus outbreaks and better prepare the public for such events. If her statement is true, then how could she possibly overlook this extremely interesting finding of RaTG13, something that clearly has the potential to infect humans? If this RaTG13 was discovered SEVEN years ago, why did Shi not publish this astonishing finding earlier? Why did she decide to publish such a sequence only when the current outbreak took place and people started questioning the origin of the Wuhan coronavirus? None of these make sense. All in all, these facts should make people question Zhengli Shi even more in terms of her possible involvement in the matter; she either was directly involved in the creation of this virus/bioweapon, or helped cover it up, or both. Of course, these facts also speak the necessity to exclude this RaTG13 sequence from any scientific analysis. The same goes to the notion that pangolins might be the intermediate host responsible for transmitting the virus from bats to humans. In early Feb, a press conference was held, where three researchers from South China Agriculture University (SCAU) claimed that their recent findings point to Pangolin as a possible intermediate host. First of all, the timing of the press conference is interesting – just when people are saying that bat viruses cannot directly infect humans and an intermediate host must exist (where the viral spike protein would “learn”/adapt to bind an ACE2 similar to human ACE2). When something MUST exist to favor the side of the CCP, this something always miraculously appears, just like Shi’s RaTG13. This time, it is the Pangolin coronavirus. Before even publishing the paper, these researchers showed their evidence – sequence of the receptor binding domain of the pangolin coronavirus that looks almost identical to the Wuhan coronavirus. Again, no live virus exists here, just the sequence (not even released back then). It is the same deal as the RaTG13 case; a person can literally type this sequence out in a few minutes. Therefore, for similar reasons, one has to be extremely cautious and alert that this may again be fabricated by the CCP with an intention to help cover up the truth. Fortunately, the field seems to have excused pangolins. The pangolin coronavirus sequence that was finally released by the SCAU group and another research group in Hong Kong fell short in convincing people about pangolin’s role as an intermediate host (4, 5). This is in part because, according to its sequence, the pangolin coronavirus also does not have the furin-cleavage site. Nonetheless, like RaTG13, these recent papers claiming the role of pangolin as an intermediate host should be discarded (4, 5). In fact, very recently, these SCAU researchers admitted to the press that, upon further analysis of the complete sequence of the Pangolin coronavirus, they also do not believe Pangolin is a possible intermediate host of the Wuhan coronavirus. Some scientific literature that deserves the spotlight We have just laid out the reasons why certain “scientific evidence” should be excluded. Now let us switch over to see why some other scientific evidence deserves our complete attention. First, the two bat coronaviruses, ZC45 and ZXC21, that are STRANGELY CLOSE to the Wuhan coronavirus were collected by a military research lab of the CCP. They published the finding and the sequences of these two viruses back in 2018 (6). I want to emphasize two facts here: 1) if the Wuhan coronavirus was man-made, then it must have been created using ZC45 or ZXC21 as a template; 2) nobody in this world has these bat coronaviruses, except for the CCP as evidenced by this publication. Second, Zhengli Shi co-authored a paper in Nature Medicine back in 2015 (7), where she collaborated with Ralph Baric at the University of North Carolina to show that replacing the spike protein of a non-human-infecting coronavirus with a spike protein capable of binding human ACE2 led to a novel coronavirus that gained the ability to infect humans. Now, what is happening in the Wuhan coronavirus essentially follows the same scheme; the changes, although minimal, are sufficient to turn the bat coronavirus into a virus that can infect humans. The only difference is that, when changes are this subtle, tracing the origin of the virus becomes much difficult. Third, a 2006 publication showed that inserting a furin-cleavage site in the junction region of S1 and S2 of spike of the SARS coronavirus led to much enhanced membrane fusion activity of the virus (8). Although viral infectivity enhancement was not observed in their study using pseudo viruses, presence of such furin-cleavage sites is known to be associated with high pathogenicity in influenza virus infections. Miraculously, this is precisely what is observed in the Wuhan coronavirus (region marked by two green lines in Figure 3). Furthermore, influenza viruses containing such furin-cleavage sites often infect a greater variety of cells and are therefore more likely to target organs in addition to the lung. Now you should recall multiple recent reports describing that the Wuhan coronavirus infects multiple organs, including lung, heart, blood vein, liver, central nerve system, etc. Simple and yet clear logic on how this Wuhan coronavirus may be made by the CCP If you put the pieces together, you should be able to appreciate how easily this virus can be created by the CCP. Obviously, the starting virus template used here, either ZC45 or ZXC21, is owned only by the CCP (6). What they would do then was to modify things such that this bat coronavirus, non-infectious to humans, could be converted to a novel coronavirus that infects humans with high efficiency. They did so by following two published concepts (7, 8): 1) they converted the crucial spike protein to something that follows the scheme of the SARS spike protein so that the virus can target human ACE2; 2) they inserted a furin-cleavage site in between S1 and S2 of spike, which may make the virus more pathogenic. These two concepts are the only ones out there to get such a job done. Yet, miraculously, they are being followed precisely here. If it were mother nature who has created this virus, then mother nature must have studied recent scientific literatures very carefully and followed these key findings faithfully in her work (2, 6-8). Also, let’s go back a little and think why they spend so much time fetching coronaviruses all over the place. Is it really like what they claimed – to understand the potentials of coronaviruses and therefore better predict future emerging coronaviruses? Why didn’t they put as much effort on vaccine research or drug discovery targeting a function/protein conserved in most coronaviruses then? The latter is not only more beneficial to the public but also way easier than predicting emerging viruses. Another possibility, of course, is that they are collecting these things to create coronavirus-based bioweapons. What is the truth? You can make up your own mind. As of me, I am fully convinced that this is a bioweapon made by the CCP. Given all the facts and the logic connecting them as laid out above, it is completely reasonable to argue that, unless the CCP can prove otherwise, the world has all the right to believe that the Wuhan coronavirus was made by the CCP. Reference 1. Daniel Wrapp NW, Kizzmekia S. Corbett, Jory A. Goldsmith, Ching-Lin Hsieh, Olubukola Abiona, Barney S. Graham, Jason S. McLellan. Cryo-EM Structure of the 2019-nCoV Spike in the Prefusion Conformation. Science. 2020. 2. Song W, Gui M, Wang X, Xiang Y. Cryo-EM structure of the SARS coronavirus spike glycoprotein in complex with its host cell receptor ACE2. PLoS Pathog. 2018;14(8):e1007236. 3. Zhou P, Yang XL, Wang XG, Hu B, Zhang L, Zhang W, et al. A pneumonia outbreak associated with a new coronavirus of probable bat origin. Nature. 2020. 4. Kangpeng Xiao JZ, Yaoyu Feng, Niu Zhou, Xu Zhang, Jie-Jian Zou, Na Li, Yaqiong Guo, Xiaobing Li, Xuejuan Shen, Zhipeng Zhang, Fanfan Shu, Wanyi Huang, Yu Li, Ziding Zhang, Rui-Ai Chen, Ya-Jiang Wu, Shi-Ming Peng, Mian Huang, Wei-Jun Xie, Qin-Hui Cai, Fang-Hui Hou, Yahong Liu, Wu Chen, Lihua Xiao, Yongyi Shen. Isolation and Characterization of 2019-nCoV-like Coronavirus from Malayan Pangolins. bioRxiv. 2020. 5. Tommy Tsan-Yuk Lam MH-HS, Hua-Chen Zhu, Yi-Gang Tong, Xue-Bing Ni, Yun-Shi Liao, Wei Wei, William Yiu-Man Cheung, Wen-Juan Li, Lian-Feng Li, Gabriel M Leung, Edward C. Holmes, Yan-Ling Hu, Yi Guan. Identification of 2019-nCoV related coronaviruses in Malayan pangolins in southern China. bioRxiv. 2020. 6. Hu D, Zhu C, Ai L, He T, Wang Y, Ye F, et al. Genomic characterization and infectivity of a novel SARS-like coronavirus in Chinese bats. Emerg Microbes Infect. 2018;7(1):154. 7. Menachery VD, Yount BL, Jr., Debbink K, Agnihothram S, Gralinski LE, Plante JA, et al. A SARS-like cluster of circulating bat coronaviruses shows potential for human emergence. Nat Med. 2015;21(12):1508-13. 8. Follis KE, York J, Nunberg JH. Furin cleavage of the SARS coronavirus spike glycoprotein enhances cell-cell fusion but does not affect virion entry. Virology. 2006;350(2):358-69.
2275 Comments
|
